最近一直都在学习使用docker,当你使用docker越久你就越发的想了解docker背后是如何实现的。其实docker的一些功能之前就已经在Linux内核中实现了,只是有些没有进入内核主线中,但是技术就是这样不会凭空产生,总是靠大量的积累,由量变到质变最后在某个时刻绽放。本文主要是介绍docker背后的内核技术namespace,cgroup,aufs。
namespace
Linux namespace主要的功能就是提供内核级别的环境隔离,这有点类似于Unix中的chroot系统调用,通过修改根目录将用户jail在一个特定的目录下,这样的jail就无法访问外部的内容,而且每一个jail的pid都是1,1意味着是当前环境下的所有进程的根节点,从而实现了环境隔离。
Linux namespace提供如下名字空间:(官方的文档namespaces in operation)1
2
3
4
5
6
7| 分类 | 系统调用参数 | 内核版本
| UTS namespace | CLONE_NEWUTS | Linux 2.6.19
| IPC namespace | CLONE_NEWIPC | Linux 2.6.19
| PID namespace | CLONE_NEWPID | Linux 2.6.24
| Mount namespace | CLONE_NEWNS | Linux 2.4.19
| USER namespace | CLONE_NEWUSER |started in Linux 2.6.23 and completed in Linux 3.8
| Network namespace | CLONE_NEWNET |started in Linux 2.6.24 and largely completed by about Linux 2.6.29
接下来介绍上述namespace的用法,可以体会一下环境隔离。(我的运行环境是ubuntu14.04,内核版本是4.3.3)
与namespace相关的API主要是以下三个:
clone():创建一个新进程,具体里面的参数自己man一下
unshare():使某个进程脱离某个namespace
setns():把某个进程加入到某个namespace
UTS namespace
UTS namespace主要实现环境隔离中的hostname隔离(测试代码加_GNU_SOURCE理由)
测试代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
/* 定义一个给 clone 用的栈,栈大小1M */
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("Container - inside the container!\n");
/* 直接执行一个shell,以便我们观察这个进程空间里的资源是否被隔离了 */
sethostname("container",10);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent - start a container!\n");
/* 调用clone函数,其中传出一个函数,还有一个栈空间的(为什么传尾指针,因为栈是反着的) */
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL);
/* 等待子进程结束 */
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
测试结果如下:
从上面的结果可以看出clone创建的进程hostname是container,和主机的ubuntu不同,从而实现了hostname的隔离。
IPC namespace
IPC全称是Inter-Process Communication,也就是进程间通信。IPC包括1
2
3
4
5
6
7| 进程间通信方式 | 主要用途
| 无名管道 |半双工,只能用于父子进程或兄弟进程之间通信
| 命名管道(FIFO)|半双工,可以用于无关进程间通信
| 消息队列 |消息队列不一定要以先进先出的次序读取,也可以按消息的类型读取
| 共享内存 |多个进程访问同一块内存空间,信号量结合使用,来达到进程间的同步及互斥
| 信号量 |作为进程间以及同一进程不同线程之间的同步手段
| 套接字 |可用于不同机器之间的进程间通信
IPC namespace实现的是限制进程间通信只能发生在同一个namespace。要启动IPC隔离,只需要在调用clone时加上CLONE_NEWIPC:1
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWIPC | SIGCHLD, NULL);
完整代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
/* 定义一个给 clone 用的栈,栈大小1M */
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("Container - inside the container!\n");
/* 直接执行一个shell,以便我们观察这个进程空间里的资源是否被隔离了 */
sethostname("contain",10);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent - start a container!\n");
/* 调用clone函数,其中传出一个函数,还有一个栈空间的(为什么传尾指针,因为栈是反着的) */
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWIPC | SIGCHLD, NULL);
/* 等待子进程结束 */
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
测试如下:
无CLONE_NEWIPC时: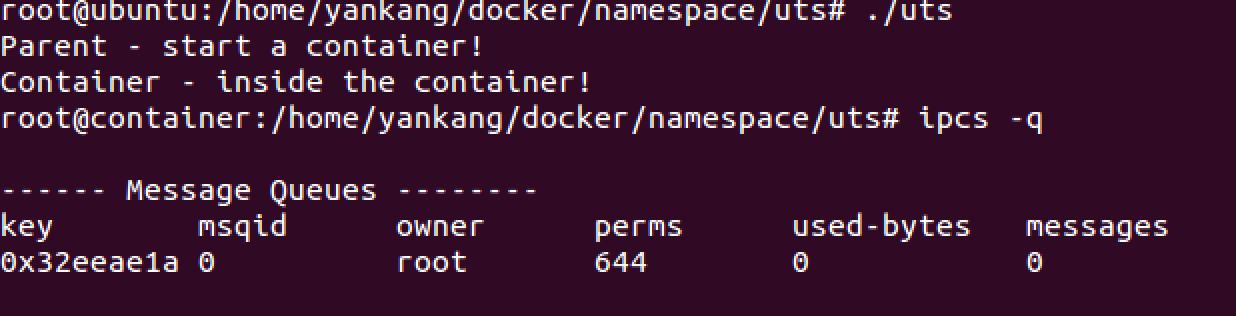
有CLONE_NEWIPC时: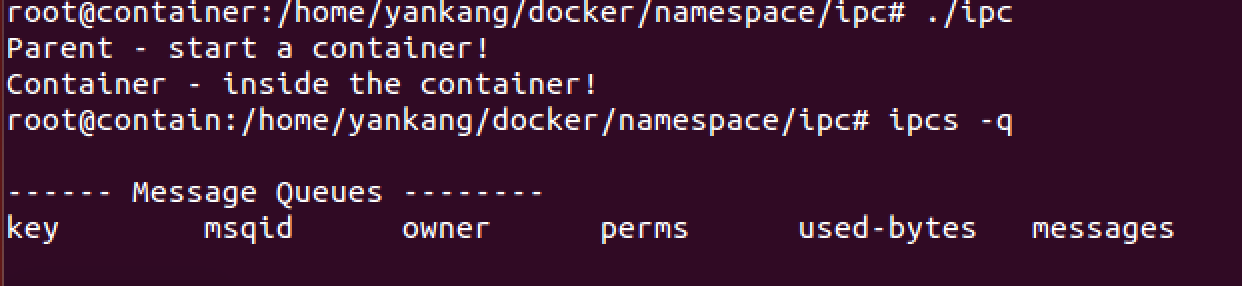
从上面的结果可以看出,IPC被隔离了,在新创建的进程中无法看到消息队列。
PID namespace
PID namespace实现的是隔离进程空间,使得新建的进程的PID是1,在传统的UNIX系统中,PID为1的进程是init,地位非常特殊。他作为所有进程的父进程,有很多特权(比如:屏蔽信号等),另外,其还会为检查所有进程的状态,我们知道,如果某个子进程脱离了父进程(父进程没有wait它),那么init就会负责回收资源并结束这个子进程。所以,要做到进程空间的隔离,首先要创建出PID为1的进程,最好就像chroot那样,把子进程的PID在容器内变成1。
现在我们在clone子进程中添加PID隔离:1
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
完整代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
/* 定义一个给 clone 用的栈,栈大小1M */
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("Container [%5d] - inside the container!\n",getpid());
/* 直接执行一个shell,以便我们观察这个进程空间里的资源是否被隔离了 */
sethostname("container",10);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent [%5d] - start a container!\n",getpid());
/* 调用clone函数,其中传出一个函数,还有一个栈空间的(为什么传尾指针,因为栈是反着的) */
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
/* 等待子进程结束 */
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
测试结果如下:
我们可以看到container的PID是1,但是有个问题,当你在子进程中输入top的时候还是会看到很多其他进程,而这些其他进程是只有父进程才看得到的,也就是说并没有完全隔离进程啊,这是因为ps, top这些命令会去读/proc文件系统,而文件系统对于父进程和子进程来说是一样的,所以还需要隔离文件系统。
Mount namespace
Mount namespace实现的是隔离挂载点,顾名思义,也就是说启动Mount namespace后不同进程挂载的文件系统是相互看不到的。所以测试代码中添加了CLONE_NEWNS,并且在子进程中加入了”mount -t proc proc /proc”来挂载/proc文件系统。
完整代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
/* 定义一个给 clone 用的栈,栈大小1M */
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("Container [%5d] - inside the container!\n",getpid());
/* 直接执行一个shell,以便我们观察这个进程空间里的资源是否被隔离了 */
sethostname("container",10);
system("mount -t proc proc /proc");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent [%5d] - start a container!\n",getpid());
/* 调用clone函数,其中传出一个函数,还有一个栈空间的(为什么传尾指针,因为栈是反着的) */
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
/* 等待子进程结束 */
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
测试结果如下:
从上图可以看出子进程的所有进程,PID为1的正好是新建的bash,另一个进程就是PS命令,这样mount的文件系统就看不到父进程空间中的进程,再比如输入top命令,也会发现进程很干净,结果如下:
USER namespace
User namespace主要是提供了用户与用户组的隔离。使用CLONE_NEWUSER这个参数,容器内部看到的UID和GID已经与外部不同了,默认显示为65534。因为容器中找不到其真正的UID,所以设置了最大的UID,可通过如下命令查看:1
cat /proc/sys/kernel/overflowuid
要把容器中的uid和真实系统的uid给映射在一起,需要修改/proc/pid/uid_map和/proc/pid/gid_map这两个文件。这两个文件的格式是:
ID-inside-ns ID-outside-ns length
ID-inside-ns表示容器里面显示的UID或GID。
ID-outside-ns表示容器外映射的真实UID或GID。
length表示映射范围,为1表示一一对应。
除了上述的格式要求,对于uid/gid的映射还有几点约束:1
2
3
4
5*)写入uid_map/gid_map的进程,必须对PID进程所属user namespace拥有[CAP_SETUID/CAP_SETGID](http://man7.org/linux/man-pages/man7/capabilities.7.html)权限
*)写入uid_map/gid_map的进程,必须位于PID进程的parent或者child USER namespace
*)另外需要满足如下条件之一:
1)父进程将有效uid/gid映射到子进程的user namespace中
2)父进程如果有CAP_SETUID/CAP_SETGID权限,那么它将可以映射到父进程中的任一uid/gid
你可以通过如下命令查看(pid表示进程编号):1
cat /proc/<pid>/uid_map
比如下面的例子表示把namespace内部从0开始的uid映射到外部从0开始的uid,其最大范围是无符号32位整形
现在我们来测试如下代码,如有不懂可以和我联系:
1 | #define _GNU_SOURCE |
上述程序运行结果如下: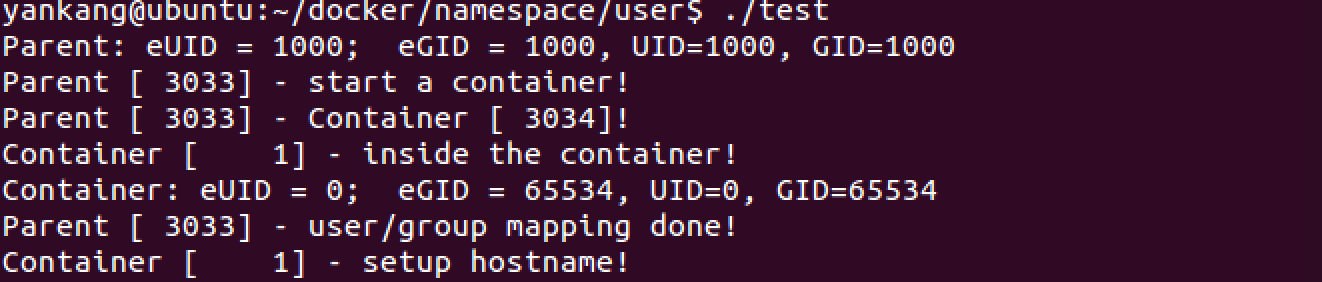
我们使用一个pipe来对父子进程进行同步,因为子进程中使用execv的系统调用,这个系统调用会把当前子进程的进程空间给全部覆盖掉,我们希望在execv之前就做好user namespace的uid/gid的映射,基于上述uid/gid的映射规则,我们需要父进程映射uid/gid,然后通知子进程可以执行execv。从而我们可以看到uid=0,就是说在容器中已经是root用户了,但是gid还不是0,是因为进程同步还没有完成,当你进入container的root用户时输入id就会发现如下的结果:
如果你的gid还不是0的话,有可能是内核版本问题,因为user namespace是在3.8以后才实现绝大部分的功能也就是说还会存在问题,比如安全性问题等。你可以想到的是我们运行程序的权限是普通用户,但是运行出来的容器是root,这样的安全性就可以得到提高,因为本质上还是普通用户,如果你想运行多个namespace可以在容器里使用root权限再创建多个namespace。
Network namespace
首先我想用一张图介绍Docker网络部分是如何连接的: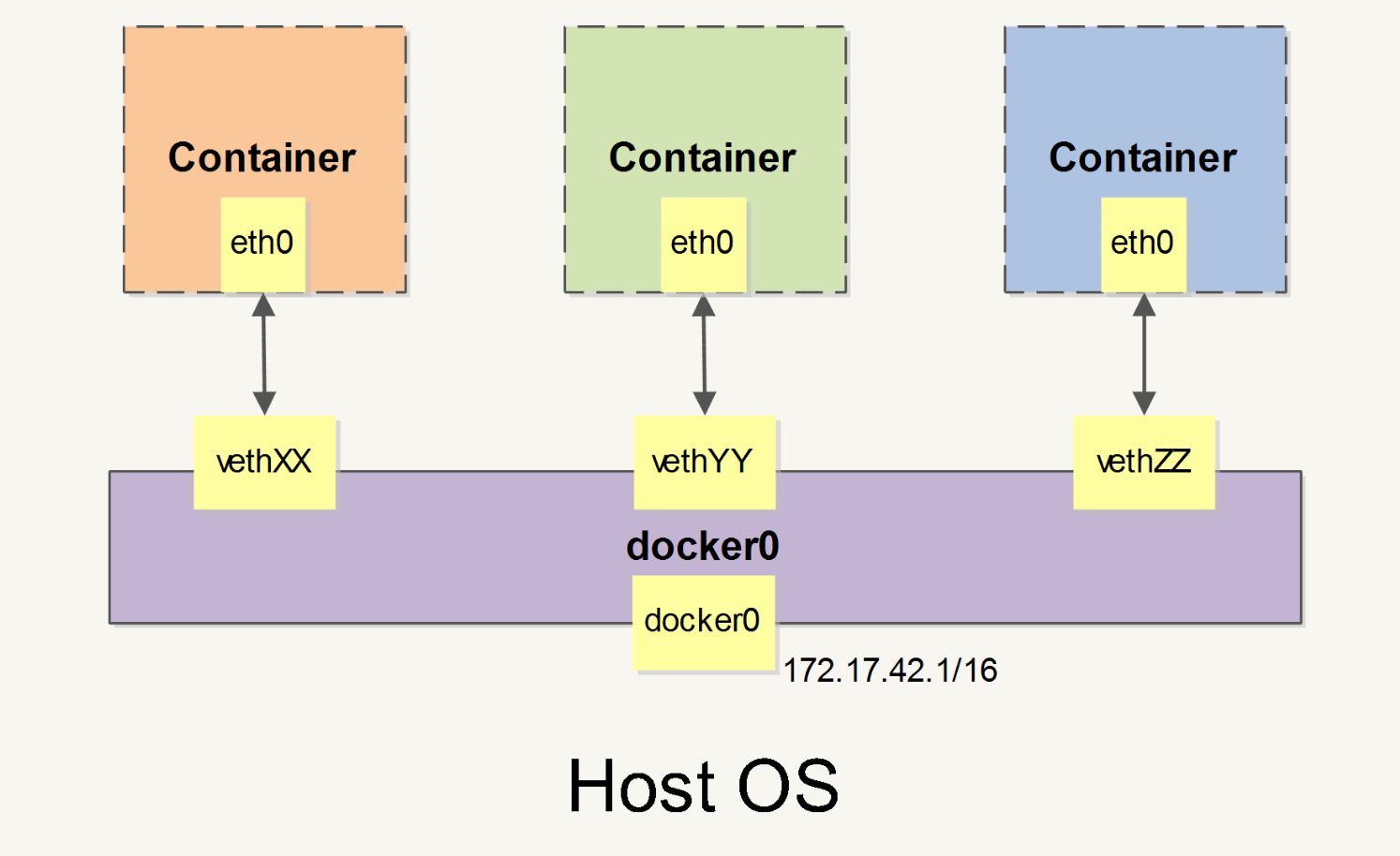
如上图所示docker0是一个虚拟网桥,可以看成是一个软件交换机。当你安装完docker后可以使用ifconfig查看docker0分配的IP,所有的容器都可以通过docker0进行通信,当然docker0上接着的容器IP和docker0的IP处于同一网段。当创建一个Docker容器的时候,同时会创建了一对veth pair接口(当数据包发送到一个接口时,另外一个接口也可以收到相同的数据包)。这对接口一端在容器内,即eth0;另一端在本地并被挂载到docker0网桥,名称以veth开头(例如vethAQI2QT)。通过这种方式,主机可以跟容器通信,容器之间也可以相互通信。Docker就创建了在主机和所有容器之间一个虚拟共享网络。
那么上述的Network命名空间如何实现的呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# 首先我们先增加一个虚拟网桥lxcbr0, 类似于docker0
brctl addbr lxcbr0
brctl stp lxcbr0 off
ifconfig lxcbr0 192.168.10.1/24 up #为网桥设置IP地址
# 增加一个namesapce命令为ns1(使用ip netns add命令)
ip netns add ns1
# 激活namespace中的loopback,即127.0.0.1(使用ip netns exec ns1来操作ns1中的命令)
ip netns exec ns1 ip link set dev lo up
## 然后,我们需要增加一对虚拟网卡
# 增加一个pair虚拟网卡,注意其中的veth类型,其中一个网卡要按进容器中
ip link add veth-ns1 type veth peer name lxcbr0.1
# 把veth-ns1按到namespace ns1中,这样容器中就会有一个新的网卡了
ip link set veth-ns1 netns ns1
# 把容器里的veth-ns1改名为eth0(容器外会冲突,容器内就不会了)
ip netns exec ns1 ip link set dev veth-ns1 name eth0
# 为容器中的网卡分配一个IP地址,并激活它
ip netns exec ns1 ifconfig eth0 192.168.10.11/24 up
# 上面我们把veth-ns1这个网卡按到了容器中,然后我们要把lxcbr0.1添加上网桥上
brctl addif lxcbr0 lxcbr0.1
# 为容器增加一个路由规则,让容器可以访问外面的网络
ip netns exec ns1 ip route add default via 192.168.10.1
# 在/etc/netns下创建network namespce名称为ns1的目录,
# 然后为这个namespace设置resolv.conf,这样,容器内就可以访问域名了
mkdir -p /etc/netns/ns1
echo "nameserver 8.8.8.8" > /etc/netns/ns1/resolv.conf
上面基本上就是docker网络的原理了,只不过,
Docker的resolv.conf没有用这样的方式,而是用了之前介绍的Mount Namesapce的那种方式
另外,docker是用进程的PID来做Network Namespace的名称的。
理解了上述过程后你可以给运行的docker容器增加一个新的网卡:1
2
3
4
5
6
7ip link add peerA type veth peer name peerB
brctl addif docker0 peerA
ip link set peerA up
ip link set peerB netns ${container-pid}
ip netns exec ${container-pid} ip link set dev peerB name eth1
ip netns exec ${container-pid} ip link set eth1 up
ip netns exec ${container-pid} ip addr add ${ROUTEABLE_IP} dev eth1
你也可以实现点对点的连接:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# 开两个sessions, 分别运行如下命令会得到两个容器ID, 比如我得到的是481和3b8
docker run -i -t --rm --net=none ubuntu:14.04 /bin/bash
docker run -i -t --rm --net=none ubuntu:14.04 /bin/bash
# 找到这两个运行容器的进程编号9166和9206
docker inspect -f '{{.State.Pid}}' 481
docker inspect -f '{{.State.Pid}}' 3b8
# 创建网络名字空间的跟踪文件
mkdir -p /var/run/netns
ln -s /proc/9166/ns/net /var/run/netns/9166
ln -s /proc/9206/ns/net /var/run/netns/9206
# 创建一对peer接口,然后配置路由
ip link add A type veth peer name B
ip link set A netns 9166
ip netns exec 9166 ip addr add 10.1.1.1/32 dev A
ip netns exec 9166 ip link set A up
ip netns exec 9166 ip route add 10.1.1.2/32 dev A
ip link set B netns 9206
ip netns exec 9206 ip addr add 10.1.1.2/32 dev B
ip netns exec 9206 ip link set B up
ip netns exec 9206 ip route add 10.1.1.1/32 dev B
# 现在这2个容器就可以相互ping通(在A中ping 10.1.1.2, B中ping 10.1.1.1),并成功建立连接。点到点链路不需要子网和子网掩码。
至此我们介绍了docker的网络命名空间,docker容器与docker0网桥连接原理,docker容器之间点对点连接的实现。
cgroup
Linux cgroup全称是linux control group,是Linux内核的一个功能,主要用来限制,控制与分离一个进程组群的资源(包括CPU计算资源,内存,磁盘IO)。
cgroup主要提供了如下功能:
Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐。
Accounting: 一些审计或一些统计,主要目的是为了计费。
Control: 挂起进程,恢复执行进程。
本质上来说,cgroup是内核附加在程序上的一系列钩子(hooks),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
接下来我们通过三个小实验来感受一下如何限制CPU资源,memory资源,磁盘IO资源。其实Linux已经把cgroup做成一个file system,可以直接mount。
限制CPU
首先我们挂载cgroup子系统。然后查看/sys/fs/cgroup/
你也可以用lssubsys命令查看cgroup能够限制哪些资源,初次使用会让你下载cgroup-bin,cgroup-bin会装上cgroup的所有子系统,如下图,我这里的测试主要是cpu,memory,blkio。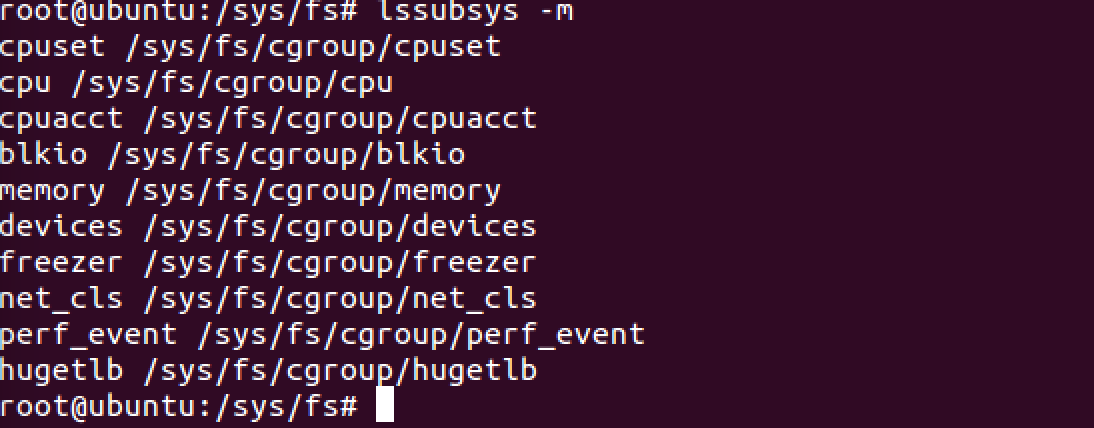
正式进入限制CPU的测试:1
2
3cd /sys/fs/cgroup/cpu
mkdir test
# 然后你会发现test目录下会生长出许多文件,表示的是限制CPU使用,限制进程数等
现在我们运行一个main.c程序如下:1
2
3
4
5
6
7
8
9
10#include<stdio.h>
int main()
{
int i=0;
while(1){
i++;
}
return 0;
}
我们会发现该程序极其损耗CPU资源,几乎达到100%:
我们将之前建立的test组做一些限制,然后发现该进程的PID是4008,将该PID加入到test组中:1
2echo 20000 > /sys/fs/cgroup/cpu/test/cpu.cfs_quota_us
echo 4008 > /sys/fs/cgroup/cpu/test/tasks
我们会发现CPU的利用率瞬间降到20%(与我们之前设置test组的20000有关):
于是就这样我们对CPU资源进行了限制的测试,当然也可以写多线程来对每个线程使用的CPU资源进行限制,类似上述的方法可以自己试试。
限制memory
同理我们在memory目录中建一个test组:1
2cd /sys/fs/cgroup/memory/
mkdir test
现在我们运行一个程序不停的分配内存:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
int size = 0;
int chunk_size = 512;
char *p = NULL;
while(1) {
if ((p = (char *)malloc(sizeof(char)*chunk_size)) == NULL) {
printf("out of memory!!\n");
break;
}
memset(p, 1, chunk_size);
size += chunk_size;
printf("[%d] - memory is allocated [%8d] bytes \n", getpid(), size);
sleep(1);
}
return 0;
}
运行上述程序: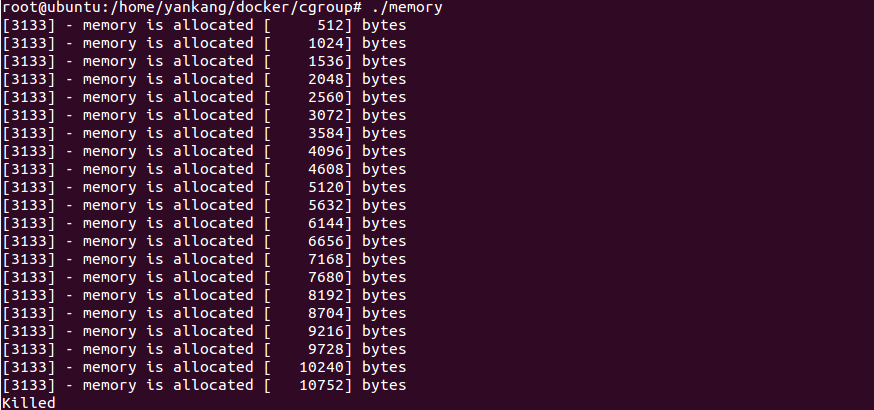
我们将之前建立的test组做一些限制,然后发现该进程的PID是3133,将该PID加入到test组中:1
2echo 10k > /sys/fs/cgroup/memory/test/memory.limit_in_bytes
echo 3133 > /sys/fs/cgroup/memory/test/tasks
于是就出现了上图中的分配到超过10kBytes时kill的情况,从而达到了限制内存的目的。
限制磁盘IO
我们来测试如何限制硬盘的IO,模拟命令如下:(从/dev/sda1上读入数据,输出到/dev/null,/dev/null是一个“黑洞”,只能写入不能读,而且写入的文件不保存)1
dd if=/dev/sda1 of=/dev/null
我们使用iotop命令测试速度如下,发现IO的速度是316.3MB/s:
当我们使用IO限制,将该IO的PID 3382加入到test组里面时,如下代码(8:0是设备号可以通过ls -l /dev/sda1获得,1048576刚好是1M):1
2echo '8:0 1048576' > /sys/fs/cgroup/blkio/test/blkio.throttle.read_bps_device
echo 3382 > /sys/fs/cgroup/blkio/test/tasks
于是结果如下
从上图可以发现我们确实将磁盘的IO操作限制在了1M,达到了限制磁盘IO的目的。
aufs
aufs是一种union file system,所谓UnionFS就是将不同物理位置的目录合并mount到同一个目录。UnionFS的一个最主要的应用是,把一张CD/DVD和一个硬盘目录给联合mount在一起,然后,你就可以对这个只读的CD/DVD上的文件进行修改(当然,修改的文件存于硬盘上的目录里)。之前在上篇博客docker入门中介绍过,docker的镜像都是只读的模版,当镜像运行在容器中的时候会在镜像的最上层添加一层可写层。如下图所示: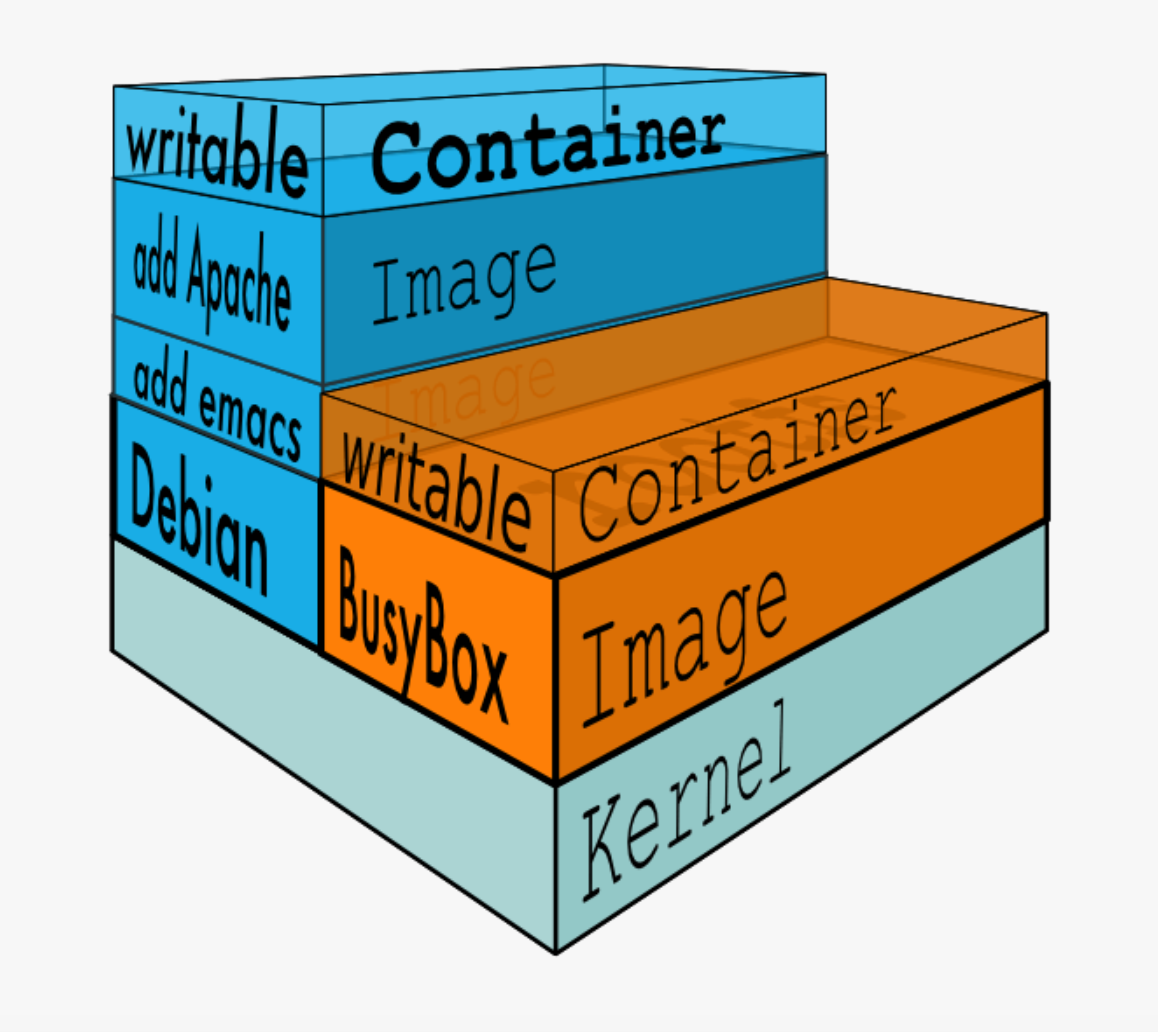
docker的分层镜像正是基于aufs实现。但是aufs并没有进入Linux内核主线(内核主线是打算发展overlayFS来取代aufs,最新的Linux内核应该已经包含overlay。),主要是Linus不让,可能是觉得aufs写得烂,也有可能是不喜欢aufs,但是很多Linux发行版都支持aufs,比如Debian,Ubuntu。Centos不支持aufs,所以其采用的是DeviceMapper(然而并没有aufs好用)。可以查看发行版是否支持aufs
也可以看看docker是aufs驱动还是DeviceMapper驱动
docker的分层镜像,除了aufs,devicemapper,docker还支持btrfs和vfs,你可以使用-s或–storage-driver= 选项来指定相关的镜像存储
接下来通过几个例子来介绍aufs
1) 测试11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 创建fruits vegetables mnt三个目录
mkdir fruits vegetables mnt
# 在fruits里创建apple,tomato两个文件,vegetables里创建carrots,tomato两个文件
cd ./fruits
touch apple tomato
cd ../vegetables
touch carrots tomato
# 将fruits和vegetables目录union mount到./mnt目录中
mount -t aufs -o dirs=./fruits:./vegetables none ./mnt
# mnt目录下会出现三个文件apple,carrots,tomato,你可能会疑问tomato是属于fruits还是vegetables,我可以先告诉你是属于fruits,后面解释为什么。
# 接下来做两个小测试
# First
echo mnt > ./mnt/apple
cat ./mnt/apple
cat ./fruits/apple
# 你会发现上述两个cat输出一样
# Second
echo mnt_carrots > ./mnt/carrots
cat ./vegetables/carrots
cat ./fruits/carrots
# 第一个cat没有任何输出,第二个cat输出了mnt_carrots,我们修改了./mnt/carrots的文件内容,./vegetables/carrots并没有变化,反而是./fruits目录中出现了carrots文件,其内容是我们在./mnt/carrots里的内容
# 原因在于我们在mount aufs命令中,并没有指定vegetables和fruits的目录权限,默认上来说,命令行上第一个(最左边)的目录是可读可写的,后面的全都是只读的,这是不是很类似docker的分层镜像?
2) 测试21
2
3
4
5
6
7
8
9
10
11
12
13# 现在我们来设置指定权限来mount aufs,先把./fruits/carrots删掉以免干扰。
mount -t aufs -o dirs=./fruits=rw:./vegetables=rw none ./mnt
# 接下来我们再做两个小实验
# First
echo "mnt_carrots" > ./mnt/carrots
cat ./vegetables/carrots
cat ./fruits/carrots
# 我们设置vegetables和fruits两个目录都是可读写的,所以第一个cat有输出,第二个cat无输出符合我们的预期。
# Second 我们来解释tomato
echo "mnt_tomato" > ./mnt/tomato
cat ./fruits/tomato
cat ./vegetables/tomato
# 我们发现第一个cat有输出,第二个cat没有输出,即是当有重复文件名的时候,在mount命令行上,越往前的优先级越高。
reference
进程间通信
Inter-Process Communication
namespace
Namespaces in operation
Linux Namespace Man Page
Creating containers - Part 1
Introduction to Linux namespaces
cgroup
Fixing control groups
The unified control group hierarchy in 3.16
Cgroup v2(PDF)
aufs
Introduce UnionFS
Union file systems: Implementations, part I
Union file systems: Implementations, part 2
Another union filesystem approach
Unioning file systems: Architecture, features, and design choices